Соответствие DE/PSC --> PHB по умолчанию
| Бит DE | PSC | PHB |
| 0 | DF > | DF |
| 0 | CSn > | CSn |
| 0 | AFn > | AFn1 |
| 1 | AFn > | AFn2 |
| 0 | EF | EF |
Соответствие PHB-->DE по умолчанию
PHB Бит DE
DF > 0
CSn > 0
AFn1 > 0
AFn2 > 1
AFn3 > 1
EF > 0
Сопряженные разработки
Существует несколько протоколов Интернет, которые так или иначе связаны с проблемой присвоения сетевых адресов. Протокол RARP (Reverse Address Resolution Protocol) [10] через расширения, описанные в DRARP (Dynamic RARP [5]), не только позволяет определить сетевой адрес, но и включает в себя автоматический механизм распределения IP-адресов. Протокол TFTP (Trivial File Transfer Protocol) [20] обеспечивает транспортировку загрузочного модуля от boot-сервера. Протокол ICMP (Internet Control Message Protocol) [16] с помощью сообщений "ICMP redirect" информирует ЭВМ о дополнительных маршрутизаторах. ICMP может также предоставить информацию о масках субсетей (сообщения "ICMP mask request"). ЭВМ могут найти маршрутизатор через ICMP-механизм поиска маршрутизаторов [8].
BOOTP является транспортным механизмом сбора конфигурационной информации. Протокол BOOTP является масштабируемым, определены стандартные расширения [17] для нескольких конфигурационных параметров. Морган предложил расширение BOOTP для динамического присвоения IP-адресов [15]. Протокол NIP (Network Information Protocol), использованный в проекте Athena МТИ, предоставляет распределенный динамический механизм выделения IP-адресов [19]. Протокол RLP (Resource Location Protocol [1]) служит для нахождения серверов, предоставляющих услуги верхнего уровня. Бездисковые рабочие станции компании Sun Microsystems используют процедуру загрузки, которая с привлечением механизма RARP, TFTP и RPC, называемого "bootparams", предоставляет бездисковой ЭВМ конфигурационную информацию и фрагменты операционной системы.
Существуют разработки, которые позволяют определить для заданного пути максимальный размер пакета (MTU) [14]. Существуют предложение по использованию протокола ARP (Address Resolution Protocol) для нахождения и выбора ресурсов [6]. Наконец, в RFC Host Requirements [3, 4] упоминаются специфические требования к конфигурированию ЭВМ, и предлагается сценарий инициализации бездисковых ЭВМ.
Состояние аннулирования запроса DRQ (Delete Request State) PEP -> PDP
При посылке это сообщение PEP указывает, что удаленный PDP, чье состояние идентифицируется дескриптором клиента, более недоступно или неверно. Эта информация будет затем использоваться удаленным PDP для инициации соответствующих служебных операций. Объект кода причины интерпретируется с учетом типа клиента и определяет причину аннулирования. Формат сообщения Delete Request State представлен ниже:
<Delete Request> ::= <Common Header>
<Client Handle>
<Reason>
[<Integrity>]
Важно, что когда состояние запроса окончательно удаляется из PEP, сообщение DRQ для состояния запроса посылается PDP, так что соответствующее состояние может быть также удалено в PDP. Состояния запроса, не удаленные явно PEP, будут поддерживаться PDP, пока не будет закрыта сессия или пока не будет разорвано соединение.
Сообщения Decision с неверным форматом должны запустить DRQ, специфицирующее соответствующий код ошибки (Bad Message Format) и любое ассоциированное состояние PEP должно быть либо удалено, либо повторно запрошено. Если Decision содержится в неизвестном объекте COPS Decision, PEP должен аннулировать его запрос, специфицирующий код причины объекта COPS Unknown, так как PEP будет неспособен работать с информацией, содержащейся в неизвестном объекте. В любом случае, после отправки DRQ, PEP может попытаться послать соответствующий запрос повторно.
Состояние отчета (RPT) PEP -> PDP
Сообщение RPT используется PEP, чтобы сообщить PDP об успехе или неудаче реализации решения PDP, или уведомить об изменении состояния. Report-Type специфицирует вид отчета и опционный ClientSI и может содержать дополнительную информацию для типа клиента.
Для каждого сообщения DEC, содержащего контекст конфигурации, которое получено PEP, он должен сформировать соответствующее сообщение-отчет о состоянии с флагом запрошенного сообщения (Solicited Message flag), который указывает на то успешно или нет реализовано конфигурационное решение. RPT-сообщения, запрошенные решением для данного дескриптора клиента, должны устанавливать флаг запрошенного сообщения и должны быть посланы в том же порядке, к каком получены соответствующие сообщения решения. Не должно быть более одного сообщения отчета о состоянии, соответствующему флагу-требованию, установленному для заданного решения.
Состояние отчета может также использоваться для реализации периодических модификаций специфической информации клиента для целей мониторирования состояния, зависящего от типа клиента. В таких случаях тип аккоунтинг-отчета должен специфицироваться с помощью соответствующего информационного объекта клиента.
<Report State> ::== <Common Header>
<Client Handle>
<Report-Type>
[<ClientSI>]
[<Integrity>]
Сосуществование деревьев с совмещением и деревьев отправителя
Некоторые протоколы поддерживают как деревья отправителя, так и деревья с совмещением (например, PIM-SM) и один маршрутизатор может содержать (*, G) и (S,G) состояния для одной и той же группы G. Два случая сосуществования описаны ниже. Рассмотрим топологии с отправителями Si и получателями Ri. RP является точкой встречи (Rendezvous Point). Ni представляют собой LSR. Числа являются номерами интерфейсов, "Reg" - интерфейс Register. Все сообщения IGMP и PIM Join/Prune показаны на рисунках. Индицируется состояние бита RPT для состояния (S,G).
1) На рис. 2 показан переход от совмещенного дерева к дереву отправителя. Предположим, что кратчайший путь от R1 к RP пролегает через N1-N2-N5. N1, выделенный маршрутизатор получателя (Designated Router) R1, (DRrecv) решает инициализировать дерево отправителя для S1. После получения данных через дерево отправителя в N2, N2 пошлет команду отсечения в N5 для отправителя S1. Состояние сосуществования реализуется в узле, где начинается перекрытие деревьев с совмещением и отправителя (N2), и в узле, где S1 не нуждается более в переадресации на дерево с совмещением (N5).

IJ=Igmp Join; PJ=Pim Join (*,G); PJS=Pim Join (S1,G); PPS=Pim Prune (S1,G)
Рис. 2
Ниже перечислены состояния, которые формируются в мультикастинг таблице маршрутизации (MRT):
в RP: (*,G):Reg->1 (т.е. входящее itf=Reg; исходящее itf=1)
в N1: (*,G):2->1
в N2: (*,G):3->1
(S1,G):2->1
в N3: (S1,G):2->Reg,1
в N4: (*,G):2->1
в N5: (*,G):2->1,3
(S1,G)RPT-бит:2->1
2) На рис. 3 показано, что состояние сосуществования может иметь место даже без переключения. Мультикастный трафик от отправителя сформирует состояние (S, G) в выделенном маршрутизаторе отправителя (DRsend; N3 на рис. 3 является DRsend отправителя S). Каждый узел совмещенного дерева имеет состояние (*,G). Таким образом Rsend имеет состояния (*, G) и (S,G). Если DRsend находится на дереве, он пошлет команду отсечения (prune) для S в направлении RP, формируя состояние (S,G) во всех узлах вплоть до первого маршрутизатора, который имеет ответвление (N1 и N2 на рис. 3).
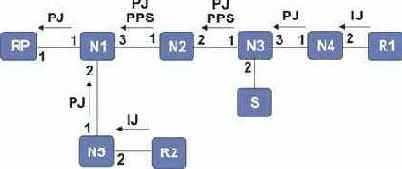
Рис. 3
Состояния, формируемые при мультикастинг-маршрутизации в MRT, представлены ниже:
в RP (*,G):Reg->1 (т.е. входящее itf=Reg; исходящее itf=1)
в N1: (*,G):1->2,3
(S,G)RPT-бит:1->2
в N2: (*,G):1->2
(S,G)RPT-бит:1->none
в N3: (*,G):1->3
(S,G):2->Reg,3
в N4: (*,G):1->2
в N5: (*,G):1->2
В данных примерах можно видеть, что могут иметь место два типа сосуществования: (S,G) с нулевым RPT-битом (N2 на рис. 2, N3 на рис. 3). Состояния (*,G) и (S,G) имеют разные входные интерфейсы, но некоторые выходные интерфейсы являются общими. Возможно, что трафик S приходит через интерфейсы (*, G) и (S,G). При обычной переадресации L3 (S,G) SPT-бит запрещает переадресацию трафика из S, приходящего через входной интерфейс (*,G). Трафик S может только временно приходить через входные интерфейсы как (*, G), так и (S,G) (вплоть до N5 на рис. 2 и N1 на рис. 3 обработали сообщения prune). Чтобы избежать временной переадресации дубликатов пакетов L3, переадресация может быть применена к этому типу узлов. Если не предполагается временной переадресации дубликатов пакетов, может быть применена переадресация на уровне L2. В этом случае потоки (*, G) и (S,G) должны быть совмещены в (*, G) LSP выходного интерфейса.(S,G) с RPT-битом =1 (N5 на рис. 2, N1 и рис. 3). Состояние (*,G) и (S,G) имеет тот же входной интерфейс. Трафик (S,G) должен извлекаться из потока (*,G). В MPLS это состояние сосуществования может обрабатываться разными способами. Будет рассмотрено четыре подхода к решению этой проблемы:
Первый метод обработки этого состояния сосуществования заключается в завершении LSP и переадресация всего трафика этой группы на L3. Однако можно избежать возврата на L3 в случае (S,G), когда к MRT не добавляется исходящий интерфейс (N2 на рис. 3). Этот вход будет принимать трафик только временно. В этом конкретном случае можно игнорировать состояние (S,G) и поддерживать существующий (*, G) LSP. Недостатком этого варианта является дублирование трафика в течение короткого времени.Вторым подходом является присвоение отправителю специфических меток для узлов, принадлежащих совмещенным деревьям. Одному набору (*, G) будет присвоено несколько меток, по одной на каждый активный источник пакетов. Так как узлы знают только, какие отправители активны, когда получают от них трафик, LSP не могут быть сформированы заранее и нужны быстрые способы установления LSP.Третий способ заключается в том, что только деревья отправителя используются для коммутации по меткам, а трафик в совмещенных деревьях всегда переадресуется на уровне L3. Это предполагает, что используются только совмещенные деревья, как средство для получателей выяснить, кто является отправителем. Конфигурируя порог переключения для низких скоростей передачи, можно гарантировать, что получатели переключаются на дерево отправителя достаточно быстро.В четвертом подходе LSR, который имеет состояние (S,G) RPT-бит с ненулевым oif, анонсирует метку для (S,G) вышестоящему LSR и это анонсирование распространяется затем каждым вышестоящим LSR в направлении RP. Таким способом выделенный LSP формируется для трафика (S,G) от RP к LSR с состоянием (S,G) RPT-бит. В последнем LSR, (S,G) LSP объединяется в (*,G) LSP для соответствующих выходных интерфейсов. Это гарантирует, что пакеты (S,G), движущиеся вдоль совмещенного дерева, не пройдут через LSR, которые отсечены от S.
Совместимость
Расширение Hello не влияет на обработку других сообщений RSVP. Единственное воздействие заключается в том, что отказ узла или канала становится известен раньше. RSVP-отклик в этом случае не изменяется.
Расширение Hello обладает полной обратной совместимостью. Классу Hello присвоено значение в форме 0bbbbbbb. В зависимости от реализации, программа, которая не поддерживает расширение, либо отбрасывает сообщения Hello либо откликается сигналом ошибки "Unknown Object Class" (неизвестный класс объекта). В любом случае отправитель не получит подтверждения на посланное Hello.
Совместимость и процедуры обработки ошибок
Возможно, что некоторые узлы вдоль LSP не будут поддерживать объект административного статуса. В случае не поддерживающего транзитного узла объект будет передан через узел без модификации и обычная обработка продолжится. В случае не поддерживающего выходного узла, объект административного состояния не будет передан назад в сообщении Resv. Чтобы поддержать вариант не поддерживающего выходного узла, входной узел должен только ждать оговоренное время. Когда период ожидания истек, входной узел посылает сообщение PathTear. По умолчанию этот период должен равняться 30 секундам.
Для того чтобы решить проблему в случае узлов, не поддерживающих объект административного состояния, необходима специальная обработка и другие условия формирования сигнала ошибки. В частности, узел, который посылает сообщение уведомления, содержащее объект административного состояния с битом D (Down) =1, должен проверять, получил ли он соответствующее сообщение Path с битом D (Down) =1 за определенный период времени, заданный при конфигурации. По умолчанию этот период должен равняться 30 секундам. Если узел не получает такого сообщения, он должен послать сообщение PathTear вниз по течению и сообщение ResvTear или PathErr с флагом Path_State_Removed =1 вверх.
Совместимость методов кодирования
Если <R1, R2, R3> является сегментом LSP, возможно, что R1 будет использовать одно представление стека меток при передачи пакета P в R2, но R2 будет использовать другое представление при передаче пакета P в R3. Вообще, архитектура MPLS поддерживает LSP с разным представлением стека меток на разных шагах маршрута. Следовательно, когда мы обсуждаем процедуры обработки помеченных пакетов, мы делаем это в терминологии взаимодействия со стеком меток. Когда приходит помеченный пакет, LSR должен декодировать его для определения текущего значения метки в стеке, затем должен преобразовать стек, чтобы определить новое значение метки перед отправкой пакета в следующий узел маршрута.
К сожалению, ATM-коммутаторы не имеют возможности осуществлять преобразование из одного представления стека меток в другое. Архитектура MPLS, следовательно, требует чтобы, когда два ATM-коммутатора оказываются последовательными LSR на уровне m LSP для определенных пакетов, эти два ATM-коммутатора используют одно и то же представление стека меток.
Естественно будут существовать MPLS сети, которые содержат комбинацию ATM-коммутаторов, работающих в качестве LSR, и других LSR, использующих MPLS заголовок-прокладку. В таких сетях могут быть некоторые LSR, имеющие ATM-интерфейсы а также интерфейсы "MPLS Shim" (прослойки). Это лишь один пример LSR с различным представлением стека меток. Такие LSR могут осуществлять подмену структур стека меток из представления ATM на входном интерфейсе в MPLS формат стека на выходном.
Совместимость с MIME
Механизмы, описанные в данном разделе являются открытыми для дальнейшего расширения. Не предполагается, что все реализации будут поддерживать все существующие типы среды. Для того чтобы обеспечить наибольшую область применимости полезно определить концепцию "MIME-совместимости", которая позволит обмениваться сообщениями, содержащими данные в формате, отличном от US-ASCII.
Почтовый агент пользователя, совместимый с MIME должен:
| (1) |
Всегда генерировать поле заголовка "MIME-Version: 1.0" в любом формируемом сообщении.
Любые не 7-битовые данные, посланные без кодирования, должны быть соответствующим образом помечены в поле content-transfer-encoding как 8-битовые или двоичные в зависимости от реального формата. Если транспортная система не поддерживает 8-битовый или двоичный формат (как, например, SMTP [RFC-821]), отправитель должен выполнить кодирование и пометить данные, как закодированные в формате base64 или закавыченных последовательностей печатных символов.
Текст:
| - |
Распознавать и отображать "текст" почтового сообщения с символьным набором "US-ASCII."
Изображение, аудио и видео:
| - | На минимальном уровне предоставить возможность обрабатывать любой не узнанный субтип, как если бы он был "application/octet-stream". |
| - | Предложить возможность удаления кодирования base64 или закавыченных последовательностей печатных символов, определенных в данном документе, если они были применены, и положить результат в файл пользователя. |
| - |
| - |
| (7) |
В частности, использование текста не US-ASCII в почтовом сообщении без поля MIME-Version категорически не рекомендуется, так как это уменьшает коммуникационные возможности. Адаптирующиеся агенты пользователя должны содержать корректные метки MIME при посылке чего-либо отличного от чистого текста с символьным набором US-ASCII.
Кроме того, агенты пользователя, не поддерживающие MIME, должны модифицироваться, если это возможно, чтобы включить соответствующую информацию заголовка MIME в отправляемое сообщение, даже если ничего более из протокола MIME не поддерживается. Эта модификация произведет малое, если вообще какое-либо влияние на получателей, не поддерживающих MIME, но поможет MIME корректно отобразить текст сообщения.
Есть и другое соображение, почему всегда безопасно посылать данные в формате, согласованным с MIME, ведь такая форма не вступит в конфликт с промежуточными почтовыми серверами, работающими в соответствие со стандартами RFC-821 и RFC-822. Агенты пользователя, которые адаптированы к MIME имеют дополнительную гарантию, что пользователю не будет представлена информация, не воспринимаемая как текст.
SPAM
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
Cлово "спам" - это компьютерный жаргон. На самом деле, спам -- это такие консервы, вроде китайского колбасного фарша, популярного в годы застоя. Расшифровывается это слово, как SPiced hAM, перченая ветчина. Слово это придумано (и зарезервировано) корпорацией Hormel.
В начале 1970-х, английские анархисты Monty Python сочинили сюрреальный скетч о спаме. Действие происходит в кафе, в котором меню состоит из спама, яичницы с беконом из спама, спама с яичницей, и беконом из спама, яичницы со спамом и сосиской из спама, сосиски из спама, спама и помидоров со спамом... (тут официантку прерывает компания викингов, сидящих за соседним столиком. Викинги поют: спам, спам, спам! вкусный спа-а-ам!)
До 1994 года, Интернет был сетью сугубо не коммерческой, а пользователями Интернета были студенты и профессора университетов. С 1994-1995 доступ к Интернет был открыт человеку с улицы, то есть торговцу. Каналы информации UseNet, прежде заполненные научными дискуссиями, порнографией или пустым трепом, были украшены сотней сообщений под заголовком типа "make money fast". Такие сообщения стали называть спамом.
Начав с конференций UseNet, спаммеры переключились на е-майл (электронную почту). Составив списки из миллионов адресов, спаммеры рассылают коммерческую рекламу сомнительных продуктов, сайтов и полулегальных услуг. В последнее время, впрочем, распространённым продуктом рекламы являются программы для рассылки спама. Купив такую программу, желающие могут разослать по 90 миллионам адресов предложение купить у них какой-нибудь товар. Спам практически ничего не стоит для отправителя - временем и деньгами за него расплачивается сплошь и рядом жертва рассылки.
Согласно исследованиям , только 9,2% пользователей читают спам сообщения. При этом данная цифра сформирована благодаря пользователям-новичкам, из тех кто провел в сети более 3 лет спам читают лишь 5,4 %.12% пользователей сети пишут возмущенные письма по обратному адресу, а 1,5 % пользователей производят вендетту (это могут быть "почтовые бомбы" в адрес злоумышленника, жалоба провайдеру и т.д.).
Спамерным атакам подвергаются не только корпоративные пользователи сети, но и владельцы домашних PC, имеющих выход в Internet. Этот факт существенно осложняет борьбу со спамом и вовлекает в неё не только самих пользователей, но и широкую общественность. В частности, 1 марта 1999 года Открытым Форумом Интернет-Сервис-Провайдеров был одобрен документ “Нормы пользования сетью” www.ofisp.org (Acceptable Use Policy), который регламентирует нормы работы в сети (в том числе накладывает ограничения на информационный шум (спам)) и обязателен для всех пользователей, а в июле минувшего года Палата Представителей США одобрила меры по борьбе со спамом. Согласно законопроекту, электронное послание должно иметь реальный обратный адрес для того, чтобы получатели спама могли заблокировать его отправителя, нарушение этого закона грозит злоумышленнику штрафом в размере до $150.000. Почему СПАМ это действительно плохо? С практической точки зрения эта проблема раскладывается на несколько компонент (RFC 2505):
Объём, т.е. пользователи получают огромное количество спам-сообщений в свои почтовые ящики.
В 99% процентах случаев содержание таких писем не коррелирует с интересами адресатов.
Для получателей СПАМ стоит реальных денег. Например, те, кто имеют выход в сеть через модем и платят за время, проведенное в Интернет, вынуждены тратить центы на фильтрацию полезных писем.
СПАМ также стоит денег и для тех, кто поддерживает и отвечает за корректную работу почтовых серверов.Предположим, что злоумышленник послал письмо объёмом 10 килобайт 10 000 пользователям на одну ЭВМ. Несложно подсчитать, сколько места займут его все его сообщения, а именно 100 мегабайт. А что произойдёт, если спамер не один и отправляет не по одному письму?
Большинство спамеров идут на всевозможные уловки, чтоб адресат взглянул хоть краем глаза на их сообщение. Например, пишут письмо таким образом, чтоб получатель подумал, что его с кем-то перепутали, или же помечают письмо так, что якобы внутри него содержится информация запрашиваемая адресатом. Разумеется, о морали и этике здесь не может идти и речи.
Признаки спам
Заголовки <Received> образуют последовательную цепочку, начиная от верхней части сообщения и заканчивая нижней частью.Любые заголовки <Received>, расположенные ниже заголовка <Date>, - поддельные.Следует обращать внимание на любой заголовок <Received>, в котором имена двух узлов не совпадают. Вероятно, почтовое сообщение было ретранслировано через первый узел (узел, имя которого заключено в круглые скобки, является действительным источником сообщения).Заголовок <Received>, имеющий старую дату, вероятнее всего, подделан.Сетевая часть заголовка <From> должна согласоваться с последним заголовком <Received>.Домен заголовка <Message-Id> должен совпадать с доменом заголовка <From>.Следует проверить, нет ли в заголовках <Received> признаков того, что сообщение ретранслировано через посторонний узел.Убедитесь, что все перечисленные узлы действительно существуют в базе данных DNSПоле <From> не должно быть пустым.Обилие в тексте опечаток и прочих искажений может также указывать на нелегальную природу сообщения, так как программа рассылки может работать без контроля подтверждений, чтобы скрыть истинный адрес рассылки.
В последнее время появилось достаточное число коммерческих и общедоступных программ фильтрации SPAM.
Спецификация действия (Action)
Действия политики в RPSL устанавливают или модифицируют атрибуты маршрутов, таких как предпочтение маршрута, добавляет атрибут BGP community или устанавливает атрибут MULTI-EXIT-DISCRIMINATOR. Действия политики могут также инструктировать маршрутизаторы по выполнению специальных операций, таких как гашение осцилляций маршрутов.
Атрибуты маршрутной политики, чьи значения могут быть модифицированы посредством действий политики, специфицированы в словаре RPSL. Каждое действие при записи в RPSL завершаются символом точка с запятой (';'). Имеется возможность формировать составные действия политики путем последовательного их перечисления. В этом случае действия выполняются в порядке слева направо. Например,
aut-num: AS1
import: from AS2 action pref = 10; med = 0; community.append(10250, 3561:10);
| accept { 128.9.0.0/16 } |
устанавливает pref = 0, med = 0, и затем добавляет 10250 и 3561:10 к атрибуту прохода community BGP. Атрибут pref является инверсным по отношению к атрибуту local-pref (т.e. local-pref == 65535 - pref). Маршрут с атрибутом local-pref всегда предпочтительнее, чем без него.
aut-num: AS1
| import: | from AS2 action pref = 1; |
| from AS3 action pref = 2; | |
| accept AS4 |
Выше приведенный пример утверждает, что маршруты AS4 получены от AS2 с предпочтением 1 и от AS3 с предпочтением 2 (маршруты с более низкими предпочтениями имеют больший приоритет, чем с большими значениями).
aut-num: AS1
| import: | from AS2 1.1.1.2 at 1.1.1.1 action pref = 1; | |
| from AS2 | action pref = 2; | |
| accept AS4 | ||
Выше приведенный пример утверждает, что маршруты AS4 получены от AS2 для направления 1.1.1.1-1.1.1.2 с предпочтением 1, а для любого другого направления от AS2 с предпочтением 2.
Спецификация LDP
Семёнов Ю.А. (ГНЦ ИТЭФ), book.itep.ru
L. Andersson RFC-3036, January 2001
Спецификация протокола
Предыдущие разделы, которые описывали работу LDP, обсуждали сценарии, которые включали обмен сообщениями между партнерами LDP. В данном разделе специфицируется кодирование сообщений и процедуры обработки сообщений.
Обмены сообщениями LDP осуществляются путем посылки протокольных данных LDP (PDU) через LDP секцию TCP соединений.
Каждый LDP PDU может содержать более одного LDP сообщения. Заметим, что сообщения в LDP PDU не обязательно должны быть связанными. Например, один PDU может содержать сообщение анонсирования FEC-метки для нескольких FEC, другое сообщение может относиться к запросу меток для ряда других FEC, а третье может быть предупреждением, сигнализирующим о каком-то событии.
Спецификация статических маршрутов
Атрибут inject может служить для спецификации статических маршрутов, используя "upon static" в качестве условия:
| inject: | [at <routerexpression>] ... |
| [action <action>] | |
| upon static |
В этом случае маршрутизатор в <router-expression> выполняет <action> и вводит маршрут в статическую маршрутную систему interAS. <action> может установить определенные маршрутные атрибуты, такие как next-hop router или cost.
В следующем примере, маршрутизатор 1.1.1.1 вводит маршрут 128.7.0.0/16. Маршрутизаторы следующего шага (в этом примере, имеется два маршрутизатора “следующего шага”) для этого маршрута имеют адреса 1.1.1.2 и 1.1.1.3, а маршрут имеет цену 10 для 1.1.1.2 и 20 для 1.1.1.3.
route: 128.7.0.0/16
origin: AS1
inject: at 1.1.1.1 action next-hop = 1.1.1.2; cost = 10; upon static
inject: at 1.1.1.1 action next-hop = 1.1.1.3; cost = 20; upon static
Спецификация структурированной политики
Политики импорта и экспорта (рассылки и приема маршрутной информации) могут быть структурированы. Применение структурированной политики рекомендуется для продвинутых пользователей RPSL. Синтаксис спецификации структурированной политики выглядит следующим образом:
| <import-factor> ::= | from <peering-1> [action <action-1>] | |
| . . . | ||
| from <peering-N> [action <action-N>] | ||
| accept <filter>; | ||
| <import-term> ::= | <import-factor> | | |
| LEFT-BRACE | ||
| <import-factor> | ||
| . . . | ||
| <import-factor> | ||
| RIGHT-BRACE | ||
| <import-expression> ::= | <import-term> | | |
| <import-term> EXCEPT <import-expression> | | | |
| <import-term> REFINE <import-expression> | ||
| import: | [protocol <protocol1>] [into <protocol2>] | |
| <import-expression> | ||
В конце <import-factor> должна быть точка с запятой. Если спецификация политики не структурирована эта точка с запятой является опционной. Синтаксис и семантика для <import-factor> определена в разделе 6.1. <import-term> представляет собой либо последовательность <import-factor>, заключенную в фигурные скобки, либо один <import-factor>. Семантика <import-term> заключается в объединении <import-factor> с использованием правила порядка спецификаций. <import-expression> представляет собой либо один <import-term>, либо <import-term>, за которым следуют ключевые слова "except" и "refine", с завершающим <import-expression>. Заметим, что данное определение допускает вложенные выражения. Следовательно, могут существовать исключения к исключениям, уточнения к уточнениям или даже уточнения к исключениям и т.д.
Семантика для оператора except имеет вид. Результатом операции исключения является еще один член <import-term>. Результирующий набор политики содержит описание политики правой стороны, но его фильтры модифицированы так, что остаются только маршруты, соответствующие левой стороне. Политика левой стороны, в конце концов, включается, а ее фильтры модифицируются так, чтобы исключить маршруты, соответствующие левой стороне. Заметим, что фильтры модифицированы во время этого процесса, но действия скопированы один к одному. При нескольких уровнях вложения операции (принять или уточнить) выполняются справа налево.
Рассмотрим следующий пример:
| import: | from AS1 action pref = 1; | accept as-foo; | |
| except | { | ||
| from AS2 action pref = 2; | accept AS226; | ||
| except | { | ||
| from AS3 action pref = 3; | accept {128.9.0.0/16}; | ||
}
}
где маршрут 128.9.0.0/16 порождается AS226, а AS226 является членом набора AS as-foo. В этом примере, маршрут 128.9.0.0/16 воспринят от AS3, любой другой маршрут (не 128.9.0.0/16) порожденный AS226 воспринимается от AS2, и любые другие маршруты AS из as-foo получены от AS1. Можно прийти к тому же заключению, используя алгебраические выкладки, определенные выше. Рассмотрим спецификацию внутреннего исключения:
from AS2 action pref = 2; accept AS226;
except { from AS3 action pref = 3; accept {128.9.0.0/16};}
Эквивалентно
{ from AS3 action pref = 3; accept AS226 AND {128.9.0.0/16};
from AS2 action pref = 2; accept AS226 AND NOT {128.9.0.0/16};}
Следовательно, исходное выражение эквивалентно:
| import: | from AS1 action pref = 1; accept as-foo; |
| except { from AS3 action pref = 3; accept AS226 AND {128.9.0.0/16}; | |
| from AS2 action pref = 2; accept AS226 AND NOT {128.9.0.0/16}; } |
| import: | { from AS3 action pref = 3; |
| accept as-foo AND AS226 AND {128.9.0.0/16}; | |
| from AS2 action pref = 2; | |
| accept as-foo AND AS226 AND NOT {128.9.0.0/16}; | |
| from AS1 action pref = 1; | |
| accept as-foo AND NOT | |
| (AS226 AND NOT {128.9.0.0/16} OR AS226 AND {128.9.0.0/16}); } |
| import: | { |
| from AS3 action pref = 3; accept {128.9.0.0/16}; | |
| from AS2 action pref = 2; accept AS226 AND NOT {128.9.0.0/16}; | |
| from AS1 action pref = 1; accept as-foo AND NOT AS226; | |
| } |
| import: | { from AS-ANY action pref = 1; accept community(3560:10); |
| from AS-ANY action pref = 2; accept community(3560:20); | |
| } refine { from AS1 accept AS1; | |
| from AS2 accept AS2; | |
| from AS3 accept AS3; } |
Здесь любому маршруту с community 3560:10 присваивается предпочтение 1 а любому маршруту с community 3560:20 присваивается предпочтение 2 вне зависимости от того, откуда они импортированы. Однако только маршруты AS1 импортированы из AS1, и только маршруты AS2 импортированы из AS2, и только маршруты AS3 импортированы из AS3, ни один маршрут не импортирован из каких-либо других AS. К тому же заключению можно прийти, используя алгебраические методы, описанные выше. То есть, это пример эквивалентен:
| import: | { |
| from AS1 action pref = 1; accept community(3560:10) AND AS1; | |
| from AS1 action pref = 2; accept community(3560:20) AND AS1; | |
| from AS2 action pref = 1; accept community(3560:10) AND AS2; | |
| from AS2 action pref = 2; accept community(3560:20) AND AS2; | |
| from AS3 action pref = 1; accept community(3560:10) AND AS3; | |
| from AS3 action pref = 2; accept community(3560:20) AND AS3; } |
| import: | { |
| from AS-ANY action med = 0; accept {0.0.0.0/0^0-18}; | |
| } refine { | |
| from AS1 at 1.1.1.1 action pref = 1; accept AS1; | |
| from AS1 action pref = 2; accept AS1; } |
| import: | { | |
| from AS1 at 1.1.1.1 action med=0; pref=1; | ||
| accept {0.0.0.0/0^0-18} AND AS1; | ||
| from AS1 action med=0; pref=2; | ||
| accept {0.0.0.0/0^0-18} AND AS1; } | ||
Ссылки
| [RSVP] |
Braden, R., Zhang, L., Berson, S., Herzog, S. and S. Jamin, "Resource ReSerVation Protocol (RSVP) Version 1 - Functional Specification", RFC-2205, September 1997. | |
| [WRK] |
Yavatkar, R., Pendarakis, D. and R. Guerin, "A Framework for Policy-Based Admission Control", RFC-2753, January 2000. | |
| [SRVLOC] |
Guttman, E., Perkins, C., Veizades, J. and M. Day, "Service Location Protocol, Version 2", RFC-2608, June 1999. | |
| [IPSEC] |
Atkinson, R., "Security Architecture for the Internet Protocol", RFC-2401, August 1995. | |
| [HMAC] |
Krawczyk, H., Bellare, M. and R. Canetti, "HMAC: Keyed-Hashing for Message Authentication", RFC-2104, February 1997. | |
| [MD5] |
Rivest, R., "The MD5 Message-Digest Algorithm", RFC-1321, April 1992. | |
| [RSVPPR] |
Braden, R. and L. Zhang, "Resource ReSerVation Protocol (RSVP) - Version 1 Message Processing Rules", RFC-2209, September 1997. | |
| [TLS] |
Dierks T. and C. Allen, "The TLS Protocol Version 1.0", RFC-2246, January 1999. | |
| [IANA] |
http://www.isi.edu/in-notes/iana/assignments/port-numbers | |
| [IANA-CONSIDERATIONS] |
Alvestrand, H. and T. Narten, "Guidelines for Writing an IANA Considerations Section in RFCs", BCP 26, RFC-2434, October 1998 |
| [1] | Acetta, M., "Resource Location Protocol", RFC-887, CMU, December 1983. |
| [2] | Alexander, S., and R. Droms, "DHCP Options and BOOTP Vendor Extensions", RFC-1533, Lachman Technology, Inc., Bucknell University, October 1993. |
| [3] | Braden, R., Editor, "Requirements for Internet Hosts -- Communication Layers", STD 3, RFC-1122, USC/Information Sciences Institute, October 1989. |
| [4] | Braden, R., Editor, "Requirements for Internet Hosts -- Application and Support, STD 3, RFC-1123, USC/Information Sciences Institute, October 1989. |
| [5] | Brownell, D, "Dynamic Reverse Address Resolution Protocol (DRARP)", Work in Progress. |
| [6] | Comer, D., and R. Droms, "Uniform Access to Internet Directory Services", Proc. of ACM SIGCOMM '90 (Special issue of Computer Communications Review), 20(4):50--59, 1990. |
| [7] | Croft, B., and J. Gilmore, "Bootstrap Protocol (BOOTP)", RFC-951, Stanford and SUN Microsystems, September 1985. |
| [8] | Deering, S., "ICMP Router Discovery Messages", RFC-1256, Xerox PARC, September 1991. |
| [9] | Droms, D., "Interoperation between DHCP and BOOTP", RFC-1534, Bucknell University, October 1993. |
| [10] | Finlayson, R., Mann, T., Mogul, J., and M. Theimer, "A Reverse Address Resolution Protocol", RFC-903, Stanford, June 1984. |
| [11] | Gray C., and D. Cheriton, "Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency", In Proc. of the Twelfth ACM Symposium on Operating Systems Design, 1989. |
| [12] | Mockapetris, P., "Domain Names -- Concepts and Facilities", STD 13, RFC-1034, USC/Information Sciences Institute, November 1987. |
| [13] | Mockapetris, P., "Domain Names -- Implementation and Specification", STD 13, RFC-1035, USC/Information Sciences Institute, November 1987. |
| [14] | Mogul J., and S. Deering, "Path MTU Discovery", RFC-1191, November 1990. |
| [15] | Morgan, R., "Dynamic IP-адрес Assignment for Ethernet Attached Hosts", Work in Progress. |
| [16] | Postel, J., "Internet Control Message Protocol", STD 5, RFC-792, USC/Information Sciences Institute, September 1981. |
| [17] | Reynolds, J., "BOOTP Vendor Information Extensions", RFC-1497, USC/Information Sciences Institute, August 1993. |
| [18] | Reynolds, J., and J. Postel, "Assigned Numbers", STD 2, RFC-1700, USC/Information Sciences Institute, October 1994. |
| [19] | Jeffrey Schiller and Mark Rosenstein. A Protocol for the Dynamic Assignment of IP-адресes for use on an Ethernet. (Available from the Athena Project, MIT), 1989. |
| [20] | Sollins, K., "The TFTP Protocol (Revision 2)", RFC-783, NIC, June 1981. |
| [21] | Wimer, W., "Clarifications and Extensions for the Bootstrap Protocol", RFC-1542, Carnegie Mellon University, October 1993. |
| [22] | G. Stump, R. Droms, Y. Gu, R., Vyaghrapuri, A. Demirtjis, B. Beser, J. Privat. The User Class Option for DHCP, RFC-3004, November 2000. |
| [23] | M. Patrick, DHCP Relay Agent Information Option. RFC-3046, January 2001. |
| [24] | |
| [25] | S. Alexander, DHCP Options and BOOTP Vendor Extensions, RFC-2132, March 1997 |
| [RFC-822] |
Crocker, D., "Standard for the Format of ARPA Internet Text Messages", STD 11, RFC-822, UDEL, August 1982. | |
| [RFC-2049] |
Borenstein, N., and N. Freed, "Multipurpose Internet Mail Extensions (MIME) Part Five: Conformance Criteria and Examples", RFC 2049, November 1996. | |
| [RFC-2045] |
Borenstein, N., and N. Freed, "Multipurpose Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies", RFC-2045, November 1996. | |
| [RFC-2046] |
Borenstein N., and N. Freed, "Multipurpose Internet Mail Extensions (MIME) Part Two: Media Types", RFC 2046, November 1996. | |
| [RFC-2048] |
Freed, N., Klensin, J., and J. Postel, "Multipurpose Internet Mail Extensions (MIME) Part Four: Registration Procedures", RFC 2048, November 1996. |
IV. Процедуры регистрации
| [ATM-VP] | N. Feldman, B. Jamoussi, S. Komandur, A, Viswanathan, T Worster, "MPLS using ATM VP Switching", Work in Progress. |
| [CRLDP] | L. Andersson, A. Fredette, B. Jamoussi, R. Callon, P. Doolan, N. Feldman, E. Gray, J. Halpern, J. Heinanen T. E. Kilty, A. G. Malis, M. Girish, K. Sundell, P. Vaananen, T. Worster, L. Wu, R. Dantu, "Constraint-Based LSP Setup using LDP", Work in Progress. |
| [DIFFSERV] | Blake, S., Black, D., Carlson, M., Davies, E., Wang, Z. and W. Weiss, "An Architecture for Differentiated Services", RFC 2475, December 1998. |
| [IANA] | Narten, T. and H. Alvestrand, "Guidelines for Writing an IANA Considerations Section in RFCs", BCP 26, RFC 2434, October 1998 |
| [RFC1321] | Rivest, R., "The MD5 Message-Digest Algorithm," RFC 1321, April 1992 |
| [RFC1483] | Heinanen, J., "Multiprotocol Encapsulation over ATM Adaptation Layer 5", RFC 1483, July 1993 |
| [RFC2328] | Moy, J., "OSPF Version 2", STD 54, RFC 2328, April 1998.RFC1700] Reynolds, J. and J. Postel, "ASSIGNED NUMBERS", STD 2, RFC 1700, October 1994 |
| [RFC1771] | Rekhter, Y. and T. Li, "A Border Gateway Protocol 4 (BGP-4)", RFC 1771, March 1995 |
| [RFC2119] | Bradner, S., "Key words for use in RFCs to Indicate Requirement Levels", BCP 14, RFC 2119, March 1997 |
| [RFC2205] | Braden, R., Zhang, L., Berson, S., Herzog, S. and S. Jamin, "Resource ReSerVation Protocol (RSVP) -- Version 1 Functional Specification", RFC 2205, September 1997 |
| [RFC2385] | Heffernan, A., "Protection of BGP Sessions via the TCP MD5 Signature Option", RFC 2385, August 1998 |
| [RFC2702] | Awduche, D., Malcolm, J., Agogbua, J., O'Dell, M. and J. McManus, "Requirements for Traffic Engineering over MPLS", RFC 2702, September 1999 |
| [RFC3031] | Rosen, E., Viswanathan, A. and R. Callon, "Multiprotocol Label Switching Architecture", RFC 3031, January 2001 |
| [RFC3032] | Rosen, E., Rekhter, Y., Tappan, D., Farinacci, D., Fedorkow, G., Li, T. and A. Conta, "MPLS Label Stack Encoding", RFC 3032, January 2001 |
| [RFC3034] | Conta, A., Doolan, P. and A. Malis, "Use of Label Switching on Frame Relay Networks Specification", RFC 3034, January 2001 |
| [RFC3035] | Davie, B., Lawrence, J., McCloghrie, K., Rekhter, Y., Rosen, E., Swallow, G. and P. Doolan, "MPLS using LDP and ATM VC Switching", RFC 3035, January 2001. |
| [RFC3037] | Thomas, B. and E. Gray, "LDP Applicability", RFC 3037, January 2001 |
|
[1] |
Braden, R., Zhang, L., Berson, S., Herzog, S. и S. Jamin, "Resource ReSerVation Protocol (RSVP) -- Version 1, Functional Specification", RFC 2205, September 1997. | ||
|
[2] |
Rosen, E., Viswanathan, A. и R. Callon, "Multiprotocol Label Switching Architecture", RFC 3031, January 2001. | ||
|
[3] |
Awduche, D., Malcolm, J., Agogbua, J., O'Dell и J. McManus, "Requirements for Traffic Engineering over MPLS", RFC 2702, September 1999. | ||
|
[4] |
Wroclawski, J., "Specification of the Controlled-Load Network Element Service", RFC 2211, September 1997. | ||
|
[5] |
Rosen, E., Tappan, D., Fedorkow, G., Rekhter, Y., Farinacci, D., Li, T. и A. Conta, "MPLS Label Stack Encoding", RFC 3032, January 2001. | ||
|
[6] |
Bradner, S., "Key words for use in RFCs to Indicate Requirement Levels", BCP 14, RFC 2119, March 1997. | ||
|
[7] |
Almquist, P., "Type of Service in the Internet Protocol Suite", RFC 1349, July 1992. | ||
|
[8] |
Nichols, K., Blake, S., Baker, F. и D. Black, "Definition of the Differentiated Services Field (DS Field) in the IPv4 и IPv6 Headers", RFC 2474, December 1998. | ||
|
[9] |
Herzog, S., "Signaled Preemption Priority Policy Element", RFC 2751, January 2000. | ||
|
[10] |
Awduche, D., Hannan, A. и X. Xiao, "Applicability Statement for Extensions to RSVP for LSP-Tunnels", RFC 3210, December 2001. | ||
|
[11] |
Wroclawski, J., "The Use of RSVP with IETF Integrated Services", RFC 2210, September 1997. | ||
|
[12] |
Postel, J., "Internet Control Message Protocol", STD 5, RFC 792, September 1981. | ||
|
[13] |
Mogul, J. и S. Deering, "Path MTU Discovery", RFC 1191, November 1990. | ||
|
[14] |
Conta, A. и S. Deering, "Internet Control Message Protocol (ICMPv6) for the Internet Protocol Version 6 (IPv6)", RFC 2463, December 1998. | ||
|
[15] |
Narten, T. и H. Alvestrand, "Guidelines for Writing an IANA Considerations Section in RFCs", BCP 26, RFC 2434, October 1998. | ||
|
[16] |
Bernet, Y., Smiht, A. и B. Davie, "Specification of the Null Service Type", RFC 2997, November 2000. |
Стек меток
До сих пор мы обсуждали проблему, как если бы помеченные пакеты несли в себе только одну метку. Как мы увидим, полезно иметь более обобщенную модель, в которой помеченные пакеты несут в себе несколько меток, уложенных в порядке “последний_вошел-первым_вышел”. Мы будем называть это стеком меток.
Хотя, как это мы увидим, MPLS поддерживает иерархию, обработка помеченных пакетов совершенно не зависит от уровня иерархии. Обработка всегда базируется на верхней метке, без учета того, что некоторое число других меток лежало поверх данной в прошлом, или того, что какое-то их число лежит под ней сейчас.
Непомеченный пакет может рассматриваться как пакет, чей стек меток пуст (т.e., глубина стека которого равна 0).
Если стек пакетных меток имеет глубину m, мы считаем, что метка на дне стека размещена на уровне 1, метка над ней (если таковая имеется) имеет уровень 2, а метка наверху стека имеет уровень m.
Стеки меток и неявное партнерство
Предположим конкретный LSR Re является прокси концом LSP для 10 адресных префиксов, и он имеет доступ к каждому адресному префиксу через отдельный интерфейс.
Можно было бы присвоить одну метку всем 10 адресным префиксам. Тогда Re будет концом LSP для всех этих префиксов. Это гарантирует, что пакеты для всех 10 адресных префиксов будут доставлены Re. Однако Re был бы должен просматривать сетевой адрес каждого такого пакета, для того чтобы правильно выбрать интерфейс, через который его следует послать.
В качестве альтернативы, можно было бы присвоить разные метки для каждого из интерфейсов. Тогда Re будет прокси концом LSP для 10 адресных префиксов. Это исключает необходимость для Re просматривать сетевые адреса пакетов, чтобы переадресовывать пакеты. Однако это может привести к использованию слишком большого числа меток.
Альтернативой может быть объединение всех 10 адресных префиксов вокруг одной общей метки уровня 1 (которая ассоциирована также с адресом самого LSR), после чего можно связать каждый адресный префикс с отдельной меткой уровня 2. Метка уровня 2 будет рассматриваться как атрибут ассоциации метки уровня 1, который мы будем называть "атрибутом стека". Мы вводим следующие правила:
- Когда LSR Ru помечает ранее непомеченные пакеты, если наилучшим соответствием адресу места назначения пакета равно X, а следующим шагом Ru LSP для X является Rd, и Rd послал Ru ассоциацию метки L1 и X, наряду с атрибутом стека L2, тогда
1. Ru должен занести в стек меток L2, а затем L1, а после этого переадресовать пакет Rd;
2. Когда Ru посылает ассоциацию метки для X своим партнерам по рассылке меток, он должен включить L2 в качестве атрибута стека.
3. Когда бы атрибут стека изменился (возможно в результате изменения следующего шага Ru LSP для X), Ru должен разослать новый атрибут стека.
Заметим, что хотя значение метки, связанное с X, может отличаться для последовательных шагов в LSP , значение атрибута стека передается без изменений, оно устанавливается узлом прокси конца LSP.
Таким образом, прокси конец LSP для X становится "неявным партнером" каждого прочего LSR в области или домене маршрутизации. В этом случае, явное партнерство было бы слишком тяжеловесным, так как число партнеров стало бы слишком большим.
Стиль SE (Shared Explicit)
Стиль SE позволяет получателю специфицировать явно список отправителей, которые должны быть включены в резервирование. Существует одно резервирование для всех отправителей, включенных в список. Так как каждый отправитель указан явно в сообщении Resv, разным отправителям могут быть присвоены различные метки, что приводит к формированию независимых LSP.
Стиль резервирования SE может быть реализован при использовании схемы маршрутов с коммутацией по меткам мультиточка-точка или при отдельных LSP для каждого отправителя. LSP мультиточка-точка могут использоваться, когда сообщения path не содержат объект EXPLICIT_ROUTE, или когда сообщения Path имеют идентичные объекты EXPLICIT_ROUTE. В любом из этих случаев может быть присвоена общая метка. Сообщения Path от различных отправителей могут содержать их собственные ERO, а пути, используемые отправителями, могут сходиться и расходиться в любой точке сети. Когда сообщения Path содержат разные объекты EXPLICIT_ROUTE, должны быть сформированы отдельные LSP для каждого объекта EXPLICIT_ROUTE.
Стиль WF (Wildcard Filter)
При стиле резервирования WF (Wildcard Filter), одно резервирование используется совместно всеми отправителями сессии. Общее резервирование в канале остается неизменным вне зависимости от числа отправителей.
Один маршрут с коммутацией по меткам со схемой мультиточка-точка формируется для всех отправителей сессии. В каналах, используемых отправителями сессии одновременно, для сессии выделяется одна метка. Если имеется только один отправитель, LSP выглядит как обычное соединение точка-точка. Когда имеется несколько отправителей, формируется LSP со схемой мультиточка-точка (реверсированное дерево).
Этот стиль полезен для приложений, в которых не все отправители передают трафик одновременно. Телефонная конференция, например, является приложением, где не все участники говорят одновременно. Если, однако, все отправители осуществляют передачу одновременно, тогда нет возможности выполнить резервирование корректно. Либо зарезервированная полоса в канале вблизи места назначения окажется меньше требуемой, либо зарезервированная полоса канала вблизи некоторых отправителей окажется больше требуемой. Это ограничивает возможность использования WF для целей управления трафиком.
Кроме того, из-за правил объединения WF, объекты EXPLICIT_ROUTE не могут использоваться для резервирования WF.
Стили резервирования
Узел получателя для каждой сессии может выбирать один из возможных стилей резервирования, а каждая сессия RSVP должна иметь определенный стиль. Отправители не имеют никакого влияния на выбор стиля резервирования. Получатель для разных LSP может выбирать различные стили резервирования. Сессия RSVP может вызывать формирование одного или более LSP, в зависимости от выбранного стиля резервирования.
Некоторые стили резервирования, такие как FF, соответствуют определенным резервированиям в конкретном узле отправителя. Другие стили резервирования, такие как WF и SE, могут реализовать совместно резервирования в нескольких узлах отправителях. Более подробное обсуждение стилей резервирования можно найти в [1].
2.4.1. Стиль FF (фиксированный фильтр)
Стиль резервирования FF (Fixed Filter) формирует определенное резервирование для трафика каждого отправителя, которое не используется совместно другими отправителями. Этот стиль является типичным для приложений, в которых трафик от каждого отправителя существует одновременно и совершенно независимо. Общее значение зарезервированной полосы пропускания для сессий, использующих FF, равно сумме резервирований для индивидуальных отправителей.
Так как каждый отправитель имеет свое собственное резервирование, для каждого из них формируется своя метка. Это может привести к формированию индивидуальных LSP туннелей для каждой пары отправитель - получатель.
Строгие и свободные субобъекты
Бит L в субобъекте является однобитовым атрибутом. Если бит L =1, тогда значение атрибута соответствует ‘свободный'. В противном случае, значение атрибута является 'строгим'. Для краткости, будем говорить, что, если значение атрибута субобъекта ‘свободный', тогда это 'свободный субобъект'. В противном случае, это 'строгий субобъект'. Более того, мы говорим, что абстрактный узел строгого или свободного субобъекта является строгим или свободным узлом, соответственно.1
Структура сообщения LDP
Все сообщения LDP имеют общую структуру, которая использует схему кодирования TLV (Type-Length-Value) тип-длина-значение; смотри раздел кодирования "Тип-длина-значение". Значение является объектом, кодируемым по схеме TLV, и может содержать одно или более TLV.

Рис. 7.
Указывает, что канал вниз по течению от этого узла защищен с помощью некоторого локального механизма восстановления. Этот флаг может =1, если только установлен флаг локальной защиты в объекте SESSION_ATTRIBUTE соответствующего сообщения Path.
0x02 Используется локальная защита
Указывает, что в данном туннеле используется локальный механизм восстановления.
Субобъект ERO метки
Субобъект ERO метки определен следующим образом:

Описание L, U и параметров метки смотри в [RFC3471].
Тип 3 метки
Длина
Поле длина содержит общую длину субобъекта в байтах, включая поля тип и длина. Длина должна быть кратной 4.
C-тип
C-тип включенного объекта метка. Копируется из объекта метка.
Субобъект IPv4 префикс

Рис. 5.
L
Содержимым префикса IPv4 субобъекта является 4-октета IPv4 адреса, 1-октет длины префикса и 1-октет заполнителя. Абстрактный узел, представляемый этим субобъектом, является набором узлов, которые имеют IP адрес в пределах этого префикса. Заметим, что длина префикса 32 указывает на один узел IPv4.
Субобъект IPv6 адрес

Рис. 8.
Тип
Указывает, что канал вниз по течению от этого узла защищен с помощью некоторого локального механизма восстановления. Этот флаг может =1, если только установлен флаг локальной защиты в объекте SESSION_ATTRIBUTE соответствующего сообщения Path.
0x02 Используется локальная защита
Указывает, что в данном туннеле используется локальный механизм восстановления.
Субобъект IPv6 префикс

Рис. 6.
L
Содержимым префикса IPv6 субобъекта является 16-октетным IPv6 адресом, 1-октет префикса длины и 1-октета заполнителя. Абстрактный узел, представляемый этим субобъектом, является набором узлов, которые имеют IP адрес в пределах этого префикса. Заметим, что длина префикса 128 указывает на один узел IPv6.
Субобъект Метка

Рис. 9.
Тип
Этот флаг указывает на то, что метка будет воспринята корректно любым интерфейсом
4.4.2. Применимость
Здесь определено использование только уникастных сессий. Существует три возможных применения RRO в RSVP. Первое, RRO может функционировать как механизм детектирования петель для выявления кольцевых маршрутов на уровне L3, или петель, сопряженных с явным маршрутом.
Второе, RRO собирает текущую маршрутную информацию шаг-за-шагом о сессиях RSVP, предоставляя ценные данные отправителю или получателю. При этом будут сообщаться любые изменения маршрута (в связи с изменением топологии сети).
Третье, синтаксис RRO сконструирован так, чтобы можно было с минимальными изменениями использовать весь объект в качестве входных данных для объекта EXPLICIT_ROUTE. Это полезно, если отправитель получает RRO от получателя в сообщении Resv, применяет его к объекту EXPLICIT_ROUTE в следующем сообщении Path, для того чтобы определить маршрут сессии.
4.4.3. Обработка RRO
Обычно, узел запускает сессию RSVP путем добавления RRO в сообщение Path. Исходное RRO содержит только один субобъект - IP-адреса отправителей. Если узел хочет также записывать метки, он устанавливает флаг Label_Recording в атрибуте SESSION_ATTRIBUTE.
Когда промежуточный маршрутизатор получает сообщение Path, содержащее RRO, он запоминает копию его блока состояния маршрута. RRO затем используется в следующем обновлении Path для форматирования сообщений Path. Когда нужно послать новое сообщение Path, маршрутизатор добавляет новый субобъект в RRO и вставляет полученный RRO в сообщение Path перед передачей.
Вновь добавляемым субобъектом должен быть IP-адрес этого маршрутизатора. Должен быть добавлен адрес интерфейса исходящего сообщения Path. Если имеется несколько адресов, выбор осуществляется исключительно локально. Однако рекомендуется, чтобы выбор адреса осуществлялся по единым правилам.
Когда флаг Label_Recording в объекте SESSION_ATTRIBUTE =1, узлы, осуществляющие запись маршрута, должны включать субобъект Label Record. Если узел использует глобальное пространство меток, тогда ему следует установить флаг Global Label.
Субобъект Label Record вводится в объект RECORD_ROUTE до введения туда IP-адреса узла. Узел не должен вводить субобъект Label Record, не вводя субобъекта IPv4 или IPv6.
Заметим, что при получении исходного сообщения Path, узел вряд ли имеет метку. Как только метка получена, узел должен включить ее в RRO при следующем обновлении Path.
Если вновь добавленный субобъект приводит к тому, что RRO оказывается слишком велико для сообщения Path (или Resv), объект RRO будет выброшен из сообщения, а обработка самого сообщения будет продолжена обычным образом. Должно быть послано отправителю (или получателю) сообщение PathErr (или ResvErr). Код ошибки будет "Notify" (внимание), а значение ошибки "RRO too large for MTU". Если получатель получает такое ResvErr, ему следует послать сообщение PathErr с кодом ошибки "Notify" и значением ошибки "RRO notification". Отправитель, получив любое из этих значений ошибок должен удалить RRO из сообщения Path.
Узлы должны повторно посылать указанные выше сообщения PathErr или ResvErr каждые n секунд, где n более 15 и обновлять интервал для сопряженного сообщения Path или RESV. Узел может применить ограничения и/или таймеры задержки, чтобы уменьшить число посылаемых сообщений.
Маршрутизатор RSVP может решить послать сообщения Path до их времени обновления, если RRO в следующем сообщении Path отличается от предыдущего. Может случиться если содержимое RRO, полученное от маршрутизатора предыдущего шага, изменяется или, если этот RRO вновь добавлен (или удален из) сообщения Path.
Когда узел назначения сессии RSVP получает сообщение Path с RRO, это указывает, что отправителю нужна запись маршрута. Узел назначения инициирует RRO процесс путем добавления RRO в сообщения Resv. Обработка отображает эти сообщения Path. Единственная разница заключается в том, что RRO в сообщении Resv записывает маршрутную информацию в обратном направлении.
Заметим, что каждый узел вдоль пути будет теперь иметь полный маршрут от отправителя до получателя. Path RRO будет иметь маршрут от отправителя до этого узла; Resv RRO будет иметь маршрут от этого узла до места назначения. Это полезно для управления сетью.
Сообщение Path, полученное без RRO, указывает, что узел отправителя не хочет более записывать маршрут. Последующие сообщения Resv не будут содержать RRO.
4.4.4. Обнаружение циклических маршрутов
В процессе обработки входящих RRO, промежуточный маршрутизатор просматривает все субобъекты, содержащиеся в RRO. Если маршрутизатор определяет, что субобъект уже содержится в списке, это означает наличие петлевого маршрута.
Сессия RSVP лишена циклов, если узлы ниже по течению получают сообщения Path или вышестоящие узлы получают сообщения Resv без маршрутных петель, обнаруженных в RRO.
Существует две широкие классификации петель переадресации. К первому классу относятся переходные петли, которые возникают при нормальной работе маршрутизаторов L3. Ко второму классу относятся постоянные петли, которые являются результатом ошибок конфигурации. Действия маршрутизатора при получении RRO зависят от типа сообщения, в котором получено RRO.
Для сообщений Path, содержащих петли переадресации, маршрутизатор формирует и посылает PathErr сообщение "Routing problem", со значение ошибки "loop detected" (обнаружена петля), после чего выбрасывает сообщение Path. Пока петля не ликвидирована, эта сессия не пригодна для переадресации информационных пакетов.
Для сообщений Resv, содержащего петлю переадресации, маршрутизатор просто отбрасывает сообщения. Сообщения Resv не должны циклить, если сообщения Path не имеют петель.
4.4.5. Прямая совместимость
Для RRO могут быть определены новые субобъекты. Когда при обработке RRO, нераспознаны субобъекты, их следует игнорировать и передавать дальше. При обработке RRO на предмет выявления петель, узел должен обходить нераспознанные при разборе объекты. Детектирование петель происходит при обнаружении субобъектов, которые выли введены самим узлом ранее. Это гарантирует, что субобъекты нужные для детектирования петель, всегда будут распознаны.
4.4.6. Отсутствие поддержки RRO
Объект RRO должен использоваться, только когда все маршрутизаторы вдоль пути поддерживают RSVP и объект RRO. Объекту RRO преписывается значение класса в форме 0bbbbbbb. Маршрутизаторы RSVP, которые не поддерживают объект будут откликаться сообщением об ошибке "Unknown Object Class" (неизвестный объект).
Субобъект Номер автономной системы
Содержимым субобъекта номера автономной системы (AS) являются два октета номера AS. Абстрактный узел, представленный субобъектом, является набором узлов, принадлежащих автономной системе. Длина номера AS субобъекта составляет 4 октета.
4.3.4. Обработка объекта Explicit Route
Субобъект RRO метки
Субобъект RRO метки имеет следующий формат:

Описания параметров U и метки смотри в [RFC3471].
Тип 3 метки
Длина смотри в [RFC3209].
Флаги смотри в [RFC3209].
C-тип C-тип включенного объекта метки. Копируется из объекта метки.
Свободный режим сохранения метки
В режиме Downstream Unsolicited, выделение меток для всех маршрутов может осуществляться всеми LDP партнерами. При использовании свободного режима сохранения меток, каждая метка, присвоенная партнером LSR, сохраняется вне зависимости от того, является ли LSR узлом следующего шага для анонсированного соответствия. При работе в режиме Downstream on Demand со свободным сохранением меток, LSR может запросить выделения меток для всех известных префиксов от всех партнеров LSR. Заметим, однако, что режим Downstream on Demand обычно используется для таких устройств, как ATM-коммутаторы, для которых рекомендуется консервативный подход.
Главным преимуществом свободного сохранения меток является то, что реакция на изменение маршрутизации может быть быстрой, так как метки уже имеются. Главным недостатком свободного режима является то, что выделяются и поддерживаются неиспользуемые метки.
Сводка кодов статуса
В , определенные в данной версии протокола. В колонке "E" представлены значения Е-бита статусного кода, требующие установки; колонка "Статусные данные" содержит 30-битовое поле статусных данных в формате TLV. Заметим, что значение F-бита статусного кода остается на усмотрение LSR, формирующего TLV статуса.
Сводка TLV
Следующие TLV определены в этой версии протокола:
| FEC | 0x0100 | TLV FEC |
| Address List | x0101 | TLV списка адресов |
| Hop Count | x0103 | TLV числа шагов |
| Path Vector | x0104 | TLV вектора пути |
| Generic Label | x0200 | TLV общей метки |
| ATM Label | x0201 | TLV метки ATM |
| Frame Relay Label | x0202 | TLV метки Frame Relay |
| Status | x0300 | TLV статуса |
| Extended Status | x0301 | Сообщение уведомления |
| Returned PDU | x0302 | Сообщение уведомления |
| Returned Message | x0303 | Сообщение уведомления |
| Common Hello | x0400 | Параметры сообщения Hello |
| IPv4 Transport Address | x0401 | Сообщение Hello |
| Configuration | x0402 | Порядковый номер сообщения Hello |
| IPv6 Transport Address | x0403 | Сообщение Hello |
| Common Session | x0500 | Параметры сообщения инициализации |
| ATM Session Parameters | x0501 | Сообщение инициализации |
| Frame Relay Session | x0502 | Параметры сообщения инициализации |
| Label Request | x0600 | ID сообщения присвоения метки |
| Vendor-Private | x3E00-0x3EFF | Частные расширения LDP производителя |
| Experimental | x3F00-0x3FFF | Экспериментальные расширения LDP |
Терминология
В данном документе применены следующие определения:
| DHCP клиент | Клиент DHCP является ЭВМ, подключенной к Интернет, которая использует DHCP, чтобы получить конфигурационные параметры, например сетевой адрес. |
| DHCP сервер | Сервер DHCP является ЭВМ, подключенной к Интернет, которая присылает клиенту DHCP параметры конфигурации. |
| Агент пересылки BOOTP |
Агент пересылки BOOTP представляет собой ЭВМ, подключенную к Интернет, или маршрутизатор, который осуществляет связь между клиентом и сервером DHCP. DHCP спроектирован так, чтобы обеспечить совместимость со спецификациями протокола BOOTP.
|
DLCI |
Метка, используемая в сетях Frame Relay для идентификации схем frame relay. | ||
|
forwarding equivalence class (FEC) |
Группа IP-пакетов, которые переадресуются каким-то образом (например, по тому же маршруту, с той же маршрутной обработкой) | ||
|
frame merge – |
Слияние меток, когда это применяется к операциям в среде, базирующейся на кадрах (frame based), так что потенциальная проблема перекрытия ячеек не является проблемой. | ||
|
Label - Метка |
Идентификатор фиксированной длины, который используется для идентификации FEC, обычно имеет локальное значение. | ||
|
label merging – |
Замещение множественных приходящих меток для определенного FEC с одной выходной меткой | ||
|
label swap – |
Базовая операция переадресации, состоящая из просмотра входной метки с целью определения выходной метки, инкапсуляции, порта и другой информации, сопряженной с обработкой поступающих данных. | ||
|
label swapping |
Парадигма переадресации, позволяющая осуществлять переадресацию данных путем использования меток для идентификации классов информационных пакетов, которые обрабатываются при переадресации неразличимым образом. | ||
|
label switched hop |
Шаг между двумя узлами MPLS, на которые осуществляется переадресация с привлечением меток. | ||
|
label switched path – путь с коммутацией меток |
Путь через один или более LSR на одном уровне иерархии для пакетов в определенном FEC. | ||
|
label switching router |
Узел MPLS, который способен переадресовывать пакеты L3 согласно их меткам | ||
|
layer 2- |
Протокольный уровень, ниже уровня 3 (который, следовательно, предлагает услуги уровню 3). Переадресация с использованием меток, происходит на уровне 2 вне зависимости от того, являлась ли рассмотренная метка ATM VPI/VCI, frame relay DLCI или метка MPLS. | ||
|
layer 3 - |
Протокольный уровень, на котором IP и ассоциированные с ним протоколы маршрутизации взаимодействуют с канальным уровнем 2. | ||
|
loop detection – |
Метод, при котором разрешено формирование петлевых маршрутов, такие структуры позднее выявляются | ||
|
loop prevention – |
Метод, при котором данные никогда не передаются по петлевым маршрутам | ||
|
label stack – стек меток |
Упорядоченный набор меток | ||
|
merge point |
Узел, в котором произведено объединение меток | ||
|
MPLS domain - |
Непрерывный набор узлов, реализующих MPLS-маршрутизацию и находящихся в одном маршрутном и административном домене. | ||
|
MPLS edge node - |
Узел MPLS, который соединяет MPLS-домен с узлом, находящимся вне домена, потому что он не поддерживает MPLS, и/или из-за того, что он размещен в другом домене. Заметим, что если LSR имеет соседнюю ЭВМ, которая не работает с MPLS, тогда этот LSR является пограничным узлом MPLS. | ||
|
MPLS egress node – |
Пограничный узел MPLS, если через него трафик выходит из домена MPLS | ||
|
MPLS ingress node – входной узел MPLS |
Пограничный узел MPLS, если через него трафик входит в домен MPLS | ||
|
MPLS label – |
Метка, которая содержится в заголовке пакета и которая представляет FEC пакета | ||
|
MPLS node – |
Узел, поддерживающий протокол MPLS. Узел MPLS распознает протоколы управления MPLS, реализует один или более протоколов маршрутизации L3, и способен переадресовывать пакеты на основе меток. Узел MPLS может опционно переадресовывать L3 пакеты в традиционном режиме. | ||
|
MultiProtocol Label Switching |
Рабочая группа IETF и разработки данной группы | ||
|
network layer – сетевой уровень |
Синоним уровня 3 | ||
|
stack |
Синоним стека меток | ||
|
switched path |
Синоним пути с коммутацией меток | ||
|
virtual circuit - |
Схема, используемая технологией обмена с установлением соединения на уровне 2, такой как ATM или Frame Relay, требующая поддержки статусной информации в переключателях уровня 2. | ||
|
VC merge – |
Объединение меток, когда метка MPLS переносится в поле ATM VCI (или в комбинации полей VPI/VCI), чтобы позволить объединение нескольких VC в один VC | ||
|
VP merge – |
Объединение меток, когда метка MPLS переносится в поле ATM VPI, чтобы позволить объединение нескольких VP в один VP. В этом случае две ячейки будут иметь одно и то же значение VCI, только если отправлены из одного узла. Это позволяет различать ячейки разных отправителей с помощью VCI. | ||
|
VPI/VCI |
Метка, используемая в сетях ATM для идентификации схем |
|
Абстрактный узел |
Группа узлов, чья исходная топология неизвестна входному узлу LSP. Абстрактный узел называется простым, если он содержит только один физический узел | ||
|
LSP, маршрутизируемый явно |
LSP, чей маршрут сформирован с помощью обычной IP-маршрутизации | ||
|
Маршрут с коммутацией по меткам |
Маршрут, сформированный путем объединения одного или более каналов с коммутацией по меткам, допускающий переадресацию пакетов одним MPLS-узлом другому такому узлу. Подробности смотри в [2]. | ||
|
LSP |
Маршрут с коммутацией по меткам (Label Switched Path) | ||
|
LSP-туннель |
LSP, который используется для туннелирования на уровне ниже чем обычная IP-маршрутизация и/или для реализации механизмов отбора | ||
|
Туннель управления трафиком (TE Tunnel) |
Набор из одного или более LSP-туннелей, которые транспортируют трафик | ||
|
Транк для трафика
|
Набор потоков, объединенных в соответствии с их классом услуг и затем помещенных в LSP или набор LSP, названный туннель управления трафиком. Подробности смотри в [3]. |
| FEC | Forwarding Equivalency Class | Класс эквивалентности переадресации |
| FTN | FEC-To-NHLFE Map | Таблица соответствия FEC и NHLFE |
| ILM | Incoming Label Map | Карта входящих меток |
| LC-ATM | Label Switching Controlled-ATM (interface) | Интерфейс АТМ, управляемый метками |
| LC-FR | Label Switching Controlled-Frame Relay (interface) | Интерфейс Frame Relay, управляемый метками |
| LSP | Label Switched Path | Путь с коммутацией по меткам |
| LSR | Label Switch Router | Маршрутизатор с коммутацией по меткам |
| MPLS | Multi-Protocol Label Switching | Многопротокольная коммутация по меткам |
| NHLFE | Next Hop Label Forwarding Entry | Рекорд следующего шага переадресации метки |
| AF | Assured Forwarding | Гарантированная переадресация |
| BA | Behavior Aggregate | Ансамбль пакетов |
| CS | Class Selector | Селектор класса |
| DF | Default Forwarding | Переадресация по умолчанию |
| DSCP | Differentiated Services Code Point | Код дифференциальных услуг |
| EF | Expedited Forwarding | Беспрепятственная переадресация |
| PHB | Per Hop Behavior | Пошаговое поведение |
| OA | Ordered Aggregate | Набор ансамблей ВА, которые придерживаются общих заказанных ограничений |
| PSC | PHB Scheduling Class | Набор из одного или более PHB, которые применяются к ансамблю ВА, принадлежащему заданному OA. Например, AF1x является PSC включающим в себя PHB AF11, AF12 и AF13. EF является примером PSC включающим в себя одно PHB, EF PHB |
В тексте используются следующие акронимы:
| CLP | Cell Loss Priority | Приоритет отбрасывания ячейки |
| DE | Discard Eligibility | Приемлемость отбрасывания |
| SNMP | Simple Network Management Protocol | Простой протокол сетевого управления |
| E-LSP | EXP-Inferred-PSC LSP | |
| L-LSP | Label-Only-Inferred-PSC LSP |
Тип услуги Intserv
Как E-LSP, так и L-LSP могут быть сформированы с или без резервирования полосы пропускания. Как это специфицировано в [RSVP_MPLS_TE], для установления E-LSP или L-LSP с резервированием полосы, используется услуга управления нагрузкой Int-Serv (или возможно гарантированная услуга) и полоса пропускания согласуется в SENDER_TSPEC (соответственно FLOWSPEC) сообщения path (соответственно Resv).
Как описано в [RSVP_MPLS_TE], для установления E-LSP или L-LSP без резервирования полосы используется служба Null, специфицированная в [NULL].
Заметим, что эта спецификация определяет использование E-LSP и L-LSP только для поддержки услуг Diff-Serv. Безотносительно к услуге Intserv (контролируемая нагрузка, Null-услуга, гарантированное обслуживание,...) и, несмотря на то, предусматривается ли резервирование полосы пропускания, E-LSP и L-LSP определены здесь для поддержки услуг Diff-Serv.
Заметим также, что эта спецификация не касается объекта DCLASS, определенного в [DCLASS], так как этот объект передает информацию о значениях DSCP, которые не существенны в сети MPLS.
Типы доступа к внешнему телу
RFC-2046 определяет тип среды message/external-body, в рамках которой объект MIME может действовать, как указатель на реальное информационное тело сообщения. Каждый указатель message/external-body специфицирует тип доступа, который определяет механизм получения реального тела сообщения. RFC-2046 определяет исходный набор типов доступа, но допустимо описание нового механизма доступа в процессе регистрации нового типа среды.
3.1. Требования к регистрации
Спецификации нового типа доступа должны отвечать ряду требований, описанных ниже.
Каждый тип доступа должен иметь уникальное имя. Это имя появляется в параметре типа доступа в поле заголовка типа содержимого message/external-body, и должно соответствовать синтаксису параметров MIME.
Все протоколы транспортные средства и процедуры, используемые данным типом доступа, должны быть описаны в самой спецификации типа доступа или в какой-то другой общедоступной спецификации, достаточно подробно, чтобы этим мог воспользоваться квалифицированный программист. Использование секретных и/или частных методов доступа категорически запрещено. Ограничения, введенные документом RFC-1602 на стандартизацию патентованных алгоритмов, также должны быть учтены.
Все типы доступа должны быть описаны в RFC. RFC может быть информационным, а не обязательно описанием стандарта.
Любые соображения безопасности, которые возникают в связи с реализацией типа доступа, должны быть подробно описаны. Совсем не нужно, чтобы метод доступа был безопасным или лишенным рисков, но известные риски должны быть идентифицированы.
3.2. Процедура регистрации
Регистрация нового типа доступа начинается с создания проекта RFC. Далее осуществляется рассылка проекта через список подписки . Для получения откликов выделяется две недели. Этот подписной лист создан для целей обсуждения предлагаемых типов среды и доступа. Предлагаемые типы доступа не должны применяться до момента формальной регистрации.
Когда двухнедельный период истечет, ответственное лицо, назначенное региональным директором IETF, переадресует запрос iana@isi.edu, или отклоняет его из-за существенных возражений, высказанных в процессе обсуждения.
Решения принятые ответственным лицом IETF рассылаются всем через подписной лист IETF-types всем заинтересованным лицам в пределах двух недель. Это решение может быть обжаловано в IESG.
Утвержденная спецификация типа доступа должна быть опубликована в качестве документа RFC. Информационные RFC публикуются путем посылки их по адресу "rfc-editor@isi.edu".
3.3. Расположение списка зарегистрированных типов доступа
Зарегистрированные спецификации типа доступа доступны через анонимное FTP на сервере . Все зарегистрированные типы доступа включаются в перечень типов доступа, периодически публикуемый в документе "Assigned Numbers" RFC-1700.
TLV числа шагов
TLV числа шагов является опционным полем в сообщениях, которые формируют LSP. Здесь на фазе формирования LSP LSR определяет число шагов.
Заметим, что процедуры формирования LSP, которые проходят через каналы ATM и Frame Relay требуют использования TLV числа шагов (смотри [RFC3035] и [RFC3034]).

Значение HC
1 октетное целое число без знака равное числу шагов.
TLV для меток в Frame Relay
LSR использует TLV метки Frame Relay, чтобы закодировать метки для каналов Frame Relay.

Res
Это поле зарезервировано. Оно должно содержать нуль при передаче и игнорироваться при приеме.
Len
Это поле специфицирует число бит DLCI. Поддерживаются следующие значения:
0 = 10 бит DLCI
2 = 23 бит DLCI
Значения Len 1 и 3 зарезервированы.
DLCI
Идентификатор соединения канала данных (Data Link Connection). По вопросам значения меток и их форматов отсылаем в [RFC3034].
TLV метки
TLV метки предназначены для кодирования меток. TLV метки содержатся в сообщениях, используемых для анонсирования, запроса и отзыва меток.
Существует несколько разных видов TLV меток, которые могут быть применены в случаях, когда требуются метки.
TLV меток ATM
LSR использует TLV ATM метки для кодирования меток, используемых в каналах ATM.

Res
Это поле зарезервировано. Оно должно содержать нуль при передаче и игнирироваться при приеме.
V-биты
Два бита переключаемых индикаторов. Если V-биты равны 00, используются как VPI, так и VCI. Если V-биты равны 01, только поле VPI имеет значение. Если V-биты = 10, значение имеет только VCI.
VPI
Идентификатор виртуального пути. Если VPI меньше 12-бит он должен быть выровнен в поле по правому краю, а свободные левые биты следует заполнить нулями.
VCI
Идентификатор виртуального канала (Virtual Channel Identifier). Если VCI имеет менее 16 бит, его следует выровнять по правому краю, а свободные левые биты заполнить нулями. Если V-биты указывают на коммутацию виртуального пути, тогда это поле должно игнорироваться получателем и устанавливаться равным нулю отправителем.
TLV списка адресов
TLV списка адресов встречаются в сообщениях адреса и отзыва адреса. Их формат представлен ниже:

Семейство адресов
Двухоктетная величина, содержащая код семейства адресов, (смотри [RFC1700]), которая определяет схему кодирования поля адреса.
Адреса
Список адресов из специфицированного семейства. Представление индивидуального адреса зависит от типа семейства адресов.
Следующие представления адресов определены данной версией протокола:
| Семейство адресов | Кодирование адресов |
| IPv4 | 4 октета полного IPv4-адреса |
| IPv6 | 16 октетов полного IPv6-адреса |
TLV статуса
Сообщения уведомления несут в себе TLV статуса, чтобы специфицировать события, о которых уведомляется адресат. Кодирование TLV состояния:

U бит
Должно быть равно нулю, когда TLV статуса послано в сообщении уведомления. Должно быть равно 1, когда TLV статуса послано в другом сообщении.
F бит
Должен быть тем же самым, что и в поле кода статуса.
Код статуса
32-битовое целое без знака, характеризующее событие. Структура кода статуса представлена ниже:

E бит
Бит фатальной ошибки. Если E=1, это уведомление о фатальной ошибке. Если Е=0, это сообщение-рекомендация.
F бит
Бит переадресации. Если F=1, уведомление должно быть переадресовано LSR для следующего или предыдущего шага LSP, ассоциированного с событием, о котором сигнализирует. Если F=0, уведомление не должно переадресовываться.
Статусные данные
30-битовое целое число без знака, которое специфицирует статусную информацию.
Эта спецификация определяет код статуса (32-битовое целое число без знака с представлением, описанным выше).
Статусный код 0 сигнализирует об успехе.
ID сообщения
Если не равно нулю, 32-битовое значение, которое идентифицирует сообщение партнера, к которому относится TLV статуса. Если нуль, то сообщение партнера не идентифицировано.
Тип сообщения
Если не равно нулю, то это тип сообщения партнера, к которому относится TLV статуса. Если нуль, то TLV статуса не относится ни к какому определенному сообщению партера.
Заметим, что использование TLV статуса не ограничивается сообщениями уведомления. Сообщение, отличное от уведомления может содержать TLV статуса в качестве опционного параметра. Когда сообщение, отличное от уведомления, содержит TLV статуса, U-бит TLV статуса должен равняться 1, чтобы индицировать, что получателю следует молча отбросить TLV, если он не готов его обработать.
TLV типовой метки
LSR использует TLV типовой метки для кодирования меток, предназначенных для использования в каналах, где значения меток не зависят от канальной технологии. Примерами таких каналов могут служить PPP и Ethernet.

Метка
Это 20-битовый код метки, как это специфицировано в [RFC3032].
TLV вектора пути
TLV вектора пути используется с TLV числа шагов в сообщениях запроса и присвоения меток, чтобы реализовать опционный механизм детектирования петель в LDP. При его использовании в сообщениях запроса метки записывается путь, по которому проходит этот запрос. При его использовании в сообщениях присвоения метки записывается путь, по которому проходит анонсирование метки в процессе формирования LSP. Его формат представлен ниже:

Один или более LSR Id
Список id маршрутизаторов, характеризующий путь, который прошло сообщение LSR. Каждый LSR Id представляет собой первые четыре октета (id маршрутизатора) идентификатора LDP для соответствующего LSR. Это гарантирует уникальность идентификатора в пределах сети LSR.
Транспортировка протокольных сообщений рассылки меток
Протокол рассылки меток используется между узлами в сети MPLS для установления и поддержания привязки меток. Для того чтобы MPLS работал корректно, информация, сопряженная с рассылкой меток, должна рассылаться совершенно надежно, а протокольные сообщения рассылки меток, имеющие отношение к определенному FEC, должны посылаться в определенном порядке. Управление потоком также желательно, так как имеется возможность транспортировки нескольких сообщений с метками в одной дейтограмме.
Одним из способов достижения цели является использование TCP в качестве базового транспортного протокола, как это делается в [MPLS-LDP] и [MPLS-BGP].
Транспортное кодирование
Транспортное кодирование представляет собой преобразование, рименяемое к типам среды MIME после конвертации в каноническую форму. Транспортное кодирование используется в нескольких целях.
| (1) |
Многие виды транспорта, особенно пересылка сообщений, могут обрабатывать только данные, состоящие из относительно коротких строк текста. Существуют также строгие ограничения на то, какие символы могут использоваться в этих строках текста. Некоторые виды транспортировки допускают использование только субнабора US-ASCII, а другие не могут работать с некоторыми символьными последовательностями. Транспортное кодирование используется, для того чтобы преобразовать двоичные данные в текстовую форму. Примеры такого сорта транспортного кодирования включают применение base64 и закавыченных строк печатных символов, определенных в RFC-2045.
Стандартизация большого числа видов транспортного кодирования представляется серьезным барьером для обеспечения совместной работы различных узлов. Несмотря ни на что, определена процедура для обеспечения средств определения дополнительных транспортных кодировок.
Требования к транспортному кодированию
Спецификации транспортного кодирования должны отвечать определенному числу требований, описанных ниже.
Каждый тип транспортного кодирования должен иметь уникальное имя. Это имя записывается в поле заголовка Content-Transfer-Encoding и должно согласовываться с его синтаксисом.
Все алгоритмы, используемые при транспортном кодировании (напр. преобразование к печатному виду или сжатие) должны быть описаны в спецификациях транспортного кодирования. Использование секретных алгоритмов транспортного кодирования категорически запрещено. Ограничения, накладываемые документом RFC-1602 на стандартизацию патентованных алгоритмов должно непременно учитываться.
Все виды транспортного кодирования должны быть применимы для произвольной последовательности октетов, имеющей любую длину. Зависимость от конкретного входного формата не допускается.
Не существует требования, чтобы транспортное кодирование приводило к определенному выходному формату. Однако выходной формат каждого транспортного кодирования должен быть исчерпывающе документирован. В частности, каждая спецификация должна ясно объявить, являются ли выходные данные 7-битовыми, 8-битовыми или просто двоичными.
Все виды транспортного кодирования должны быть полностью инвертируемыми на любой платформе. Всегда должна иметься возможность преобразовать данные к исходному виду с помощью соответствующей декодирующей процедуры. Заметим, что эти требования исключают все виды сжатия с частичной потерей информации и все виды шифрования в качестве разновидностей транспортного кодирования.
Все виды транспортного кодирования должны предоставлять некоторый вид новых функциональных возможностей.
4.2. Процедура определения транспортного кодирования
Определение нового вида транспортного кодирования начинается с создания проекта стандартного документа RFC. RFC должен определить транспортное кодирование точно и исчерпывающе и предоставить необходимое обоснование введения этого вида кодирования. Эта спецификация должна быть представлена на рассмотрение IESG. IESG может
| (1) | отклонить спецификацию, как неприемлемую для стандартизации, |
| (2) |
одобрить создание рабочей группы IETF для разработки спецификации, согласно действующей процедуре IETF, или
4.3. Процедуры IANA для регистрации транспортного кодирования
Не существует необходимости для специальной процедуры регистрации транспортного кодирования IANA. Все стандартные транспортные виды кодирования должны быть оформлены в виде RFC, таким образом, ответственность по информированию IANA об одобрении нового вида транспортного кодирования лежит на IESG.
4.4. Размещение списка зарегистрированных видов транспортного кодирования
Регистрационные материалы по всем стандартизованным видам транспортного кодирования доступны через анонимное FTP на сервере . Все зарегистрированные типы транспортного кодирования обязательно заносятся в списки документа "Assigned Numbers" [RFC-1700].
V. Критерии совместимости и примеры
Далее рассмотрено, какие части MIME должны поддерживаться MIME-совместимой программной реализацией.
Туннель, маршрутизированный явно
Если туннелированный пакет транспортируется из Ru в Rd по пути, отличному от маршрута шаг-за-шагом, мы говорим, что это "Туннель, маршрутизированный явно" с начальной точкой в Ru и конечной - в Rd. Например, мы можем послать пакет через туннель, маршрутизированный явно путем инкапсуляции его в пакет, маршрутизируемый отправителем.
Туннель, маршрутизированный шаг-за-шагом
Если туннелированный пакет следует маршрутом шаг-за-шагом от Ru к Rd , мы говорим, что это "туннель, маршрутизированный шаг-за-шагом", чье начало находится в Ru и чей конец в Rd.
Туннели и иерархия
Иногда маршрутизатор Ru предпринимает действия, чтобы доставить определенный пакет другому маршрутизатору Rd, даже если Ru и Rd не являются смежными углами на пути пакета, а Rd не является местом назначения пакета. Это может быть сделано, например, путем инкапсуляции пакета в пакет сетевого уровня, местом назначения которого является Rd. Это создает туннель от Ru к Rd .
Туннели LSP
Имеется возможность реализовать туннель в виде LSP и использовать коммутацию меток, а не инкапсуляцию сетевого уровня, чтобы заставить пакет идти через туннель. Туннель будет иметь вид LSP <R1, ..., Rn >, где R1 является началом туннеля, а Rn – концом туннеля. Это называется " LSP-туннелем".
Набор пакетов, которые посланы через LSP-туннель, представляет собой FEC, а каждый LSR в туннеле должен установить ассоциацию между меткой и FEC (т.e., нужно присвоить туннелю определенную метку). Критерий установления соответствия пакета LSP-туннелю является внутренним вопросом начальной точки туннеля. Чтобы направить пакет в LSP-туннель, передающий конец туннеля вводит метку туннеля в стек и посылает помеченный пакет узлу следующего шага туннеля.
Если для конечной точки туннеля не нужно определять, какой пакет получен через туннель, как это обсуждалось выше, стек меток может быть очищен на предпоследнем LSR туннеля.
" LSP-туннель, маршрутизированный шаг-за-шагом" представляет собой туннель, который реализован в виде LSP-туннеля, маршрутизированного по схеме шаг-за-шагом. "LSP-туннелем, маршрутизированным явно" является LSP-туннель, который представляет собой также LSP, маршрутизированный явно.